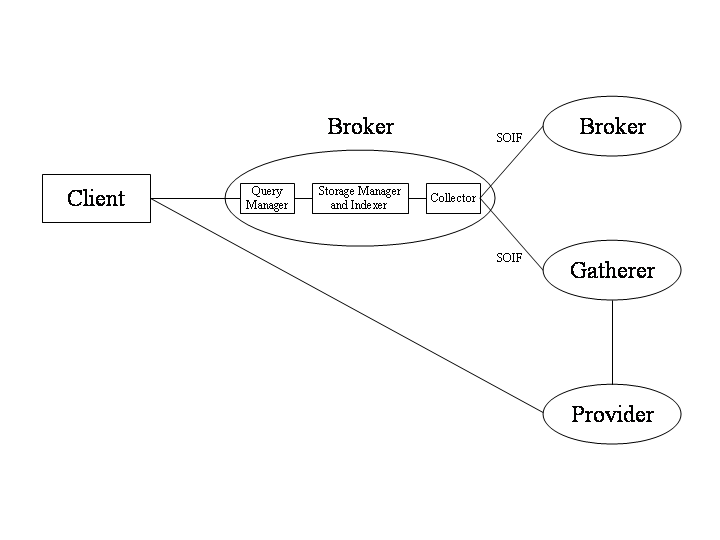
Harvest consists of several subsystems. The Gatherer subsystem collects indexing information (such as keywords, author names, and titles) from the resources available at Provider sites (such as FTP and HTTP servers). The Broker subsystem retrieves indexing information from one or more Gatherers, suppresses duplicate information, incrementally indexes the collected information, and provides a WWW query interface to it.
You should start using Harvest simply, by installing a single ``stock'' (i.e., not customized) Gatherer and Broker on one machine to index some of the FTP, World Wide Web, and NetNews data at your site.
After you get the system working in this basic configuration, you can invest additional effort as warranted. First, as you scale up to index larger volumes of information, you can reduce the CPU and network load to index your data by distributing the gathering process. Second, you can customize how Harvest extracts, indexes, and searches your information, to better match the types of data you have and the ways your users would like to interact with the data.
We discuss how to distribute the gathering process in the next subsection. We cover various forms of customization in Section Customizing the type recognition, candidate selection, presentation unnesting, and summarizing steps and in several parts of Section The Broker.
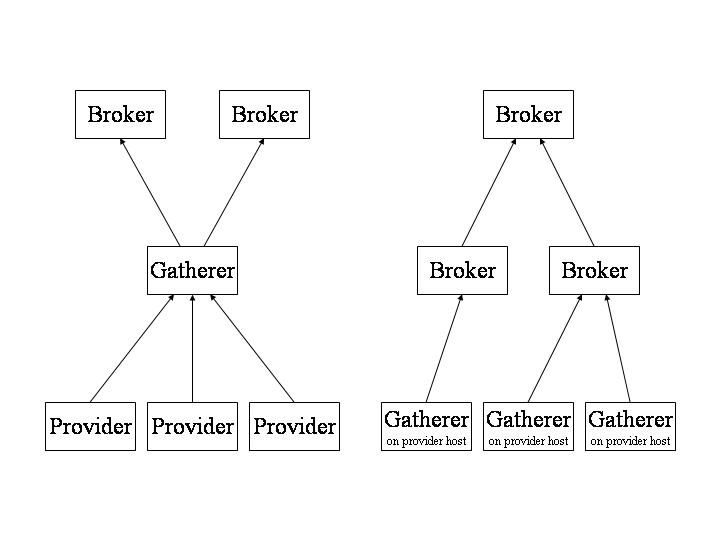
Harvest Gatherers and Brokers can be configured in various ways. Running a Gatherer remotely from a Provider site allows Harvest to interoperate with sites that are not running Harvest Gatherers, by using standard object retrieval protocols like FTP, Gopher, HTTP, and NNTP. However, as suggested by the bold lines in the left side of Figure 2, this arrangement results in excess server and network load. Running a Gatherer locally is much more efficient, as shown in the right side of Figure 2. Nonetheless, running a Gatherer remotely is still better than having many sites independently collect indexing information, since many Brokers or other search services can share the indexing information that the Gatherer collects.
If you have a number of FTP/HTTP/Gopher/NNTP servers at your site, it is most efficient to run a Gatherer on each machine where these servers run. On the other hand, you can reduce installation effort by running a Gatherer at just one machine at your site and letting it retrieve data from across the network.
Figure 2 also illustrates that a Broker can collect information from many Gatherers (to build an index of widely distributed information). Brokers can also retrieve information from other Brokers, in effect cascading indexed views from one another. Brokers retrieve this information using the query interface, allowing them to filter or refine the information from one Broker to the next.